
Humans exhibit an innate capacity to rapidly perceive and segment objects from video observations, and even mentally assemble them into structured 3D scenes. Replicating such capability, termed compositional 3D reconstruction, is pivotal for the advancement of Spatial Intelligence and Embodied AI. However, existing methods struggle to achieve practical deployment due to the insufficient integration of cross-modal information, leaving them dependent on manual object prompting, reliant on auxiliary visual inputs, and restricted to overly simplistic scenes by training biases. To address these limitations, we propose ReplicateAnyScene, a framework capable of fully automated and zero-shot transformation of casually captured videos into compositional 3D scenes. Specifically, our pipeline incorporates a five-stage cascade to extract and structurally align generic priors from vision foundation models across textual, visual, and spatial dimensions, grounding them into structured 3D representations and ensuring semantic coherence and physical plausibility of the constructed scenes. To facilitate a more comprehensive evaluation of this task, we further introduce the C3DR benchmark to assess reconstruction quality from diverse aspects. Extensive experiments demonstrate the superiority of our method over existing baselines in generating high-quality compositional 3D scenes.
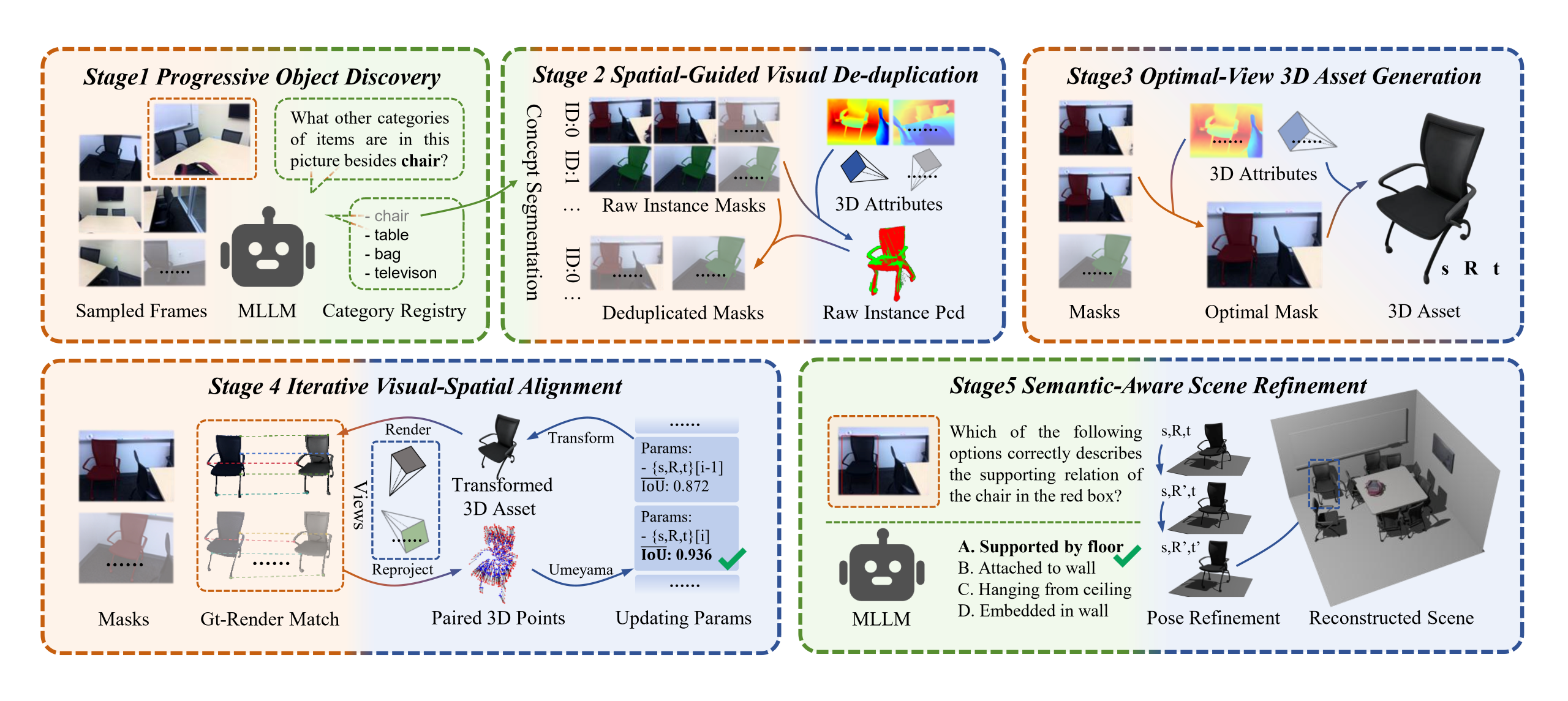
Overview of ReplicateAnyScene. We present a zero-shot video-to-3D composition framework based on textual-visual-spatial alignment for transforming casually captured videos into compositional 3D scenes.


@misc{dong2026replicateanyscenezeroshotvideoto3dcomposition,
title={ReplicateAnyScene: Zero-Shot Video-to-3D Composition via Textual-Visual-Spatial Alignment},
author={Mingyu Dong and Chong Xia and Mingyuan Jia and Weichen Lyu and Long Xu and Zheng Zhu and Yueqi Duan},
year={2026},
eprint={2604.10789},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2604.10789},
}